The World has always been full of data, but with the digitalization in this century, its limits have grown unpredictably. Focusing on the rapidly growing digital data has been a major priority, particularly for businesses. The job of acquiring, processing, and harnessing these vast amounts of data is undoubtedly Data Science. Let’s start with the article, where we won’t leave any questions unanswered.

Data Science History
The term “Data Science” was coined in the 1960s to describe a new profession that would aid in comprehending and analyzing the massive volumes of data that were amassing at the time. It is a discipline that uses computer science and statistical methodology to produce meaningful predictions and obtain insights into various industries. It is used not only in fields such as astronomy and medicine but also in business to make better decisions.
Statistics and the application of statistical models are firmly ingrained in the discipline. Since its inception in statistics, it has evolved to encompass concepts and techniques such as machine learning, artificial intelligence, and the IoT (Internet of Things), to name a few examples. Businesses have been gathering and keeping ever-increasing volumes of data as it has become available, first through recorded purchasing behaviors and trends.
A flood of new information, known as big data, has poured into the world as the Internet, IoT and the rapid increase in data quantities available to enterprises have grown in importance. As corporations began to use big data to increase revenues and generate wise decisions, the use of big data moved to other areas such as medicine, engineering, and disciplines such as sociology and other industries.
Unlike a typical statistician, a functional data scientist understands software architecture and various programming languages. The data scientist describes the problem, identifies critical sources of information, and creates the structure for gathering and screening the necessary data. Typically, the software is in charge of data collection, processing, and modeling. They apply principles, as well as all of the related sub-fields and techniques that fall under the purview of it, to get a better understanding of the data assets under consideration.

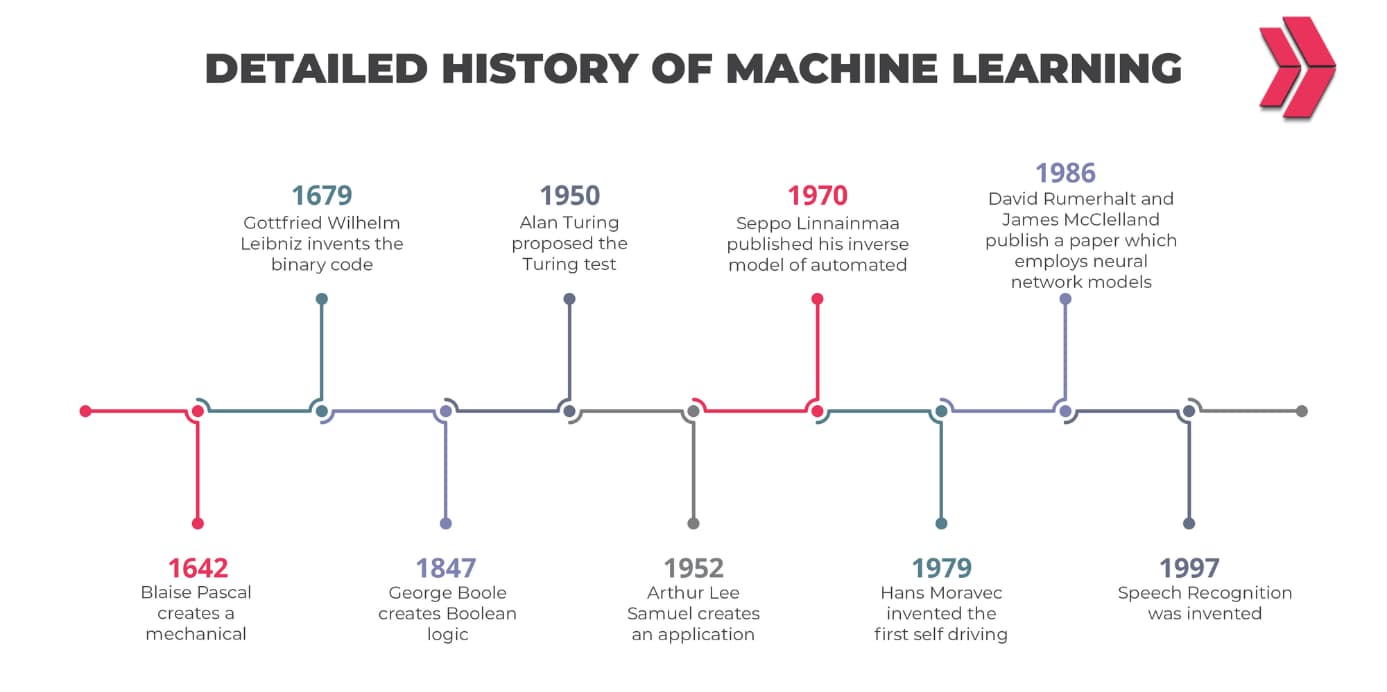
There are numerous growth dates, and the most important of which are listed in the timeline below.
Data Science Timeline
- In 1962, John Tukey mentioned the fusion of statistics and computers in his papers named “The Future of Data Analysis”.
- In 1974, Peter Naur introduced a new concept of processing the data by using the term “Data Science” constantly.
- In 1977, IASC (The International Association for Statistical Computing) was constituted.
- In 1977, In his book “Exploratory Data Analysis,” John Tukey proposed that residuals be explicitly analyzed for system tendencies.
- In 1989, the first workshop on Knowledge Discovery in Databases was organized.
- In 1994, Business Week magazine published its cover story, Database Marketing, about creating marketing campaigns by collecting large amounts of personal data.
- In 1999, In his post titled Mining Data for Nuggets of Knowledge, Jacob Zahavi emphasized the necessity of new tools to manage the huge and ever-expanding volumes of data usable to enterprises.
- In 2001, Software-as-a-Service (SaaS) was launched.
- In 2001, with the publication Data Science: An Action Plan for Expanding the Technical Areas of the Field of Statistics, William S. Cleveland laid forth ideas for training data scientists to meet the needs of the future.
- In 2002, Data Science Journal started publication.
- In 2006, an open-source and non-relational database, Hadoop 0.1.0, was released. The storage of massive volumes of data, followed by processing, are two issues for big data processing. Hadoop fixed those issues.
- In 2008, the term “data scientist” became commonplace.
- In 2009, Johan Oskarsson revived the term NoSQL when he arranged a conversation on “open-source, non-relational databases.”
- In 2011, Job postings for data scientists had surged by 15,000%.
- In 2013, IBM released statistics indicating that 90 % of data was made all around the World in the last two years.
- In 2015, Google’s speech recognition service, Google Voice, saw a 49 percent improvement in performance using deep learning algorithms.
- In 2015, According to Bloomberg’s Jack Clark, 2015 was a watershed moment for artificial intelligence (AI). Over the course of the year, Google’s overall number of AI-powered software projects climbed to around 3000.

Data Science Today
In the past, Data Science has discreetly expanded to cover enterprises and organizations worldwide. Organizations, biologists, scientists, and even physicists are now using it. Throughout its history, its use of big data involved not just scaling up the data, but also migrating to new technologies for processing data and changing the ways data is researched and evaluated.
Data Science has emerged as a significant component of both business and academia. Translation, robotic systems, and search engines are all examples of this. In addition, it has broadened its research topics to encompass biology, medical services, and anthropology. Also, it currently impacts economy, government, business, and finance.
What is Data Science?
Data science is a field that combines several disciplines, including statistics, scientific techniques, artificial intelligence (AI), and data analysis, in order to derive value from data. Data scientists are those who integrate a variety of talents to analyze data acquired from the web, smartphones, customers, and sensors, among other sources, to generate actionable insights.
The term “data science” refers to the preparation of data for analysis, which involves cleansing, aggregation, and manipulating data to do advanced data analysis. As a result, analytical programs and data scientists may then evaluate the information to identify trends and assist corporate executives in making educated decisions.
Why is Data Science so Important?
Because businesses have a great wealth of data, data volumes have grown as modern technology has made it easier to create and store an increased volume of data. Over the last few years, upwards of 90% of the world’s data has been acquired. For instance, social media users post over 20 million images every hour.
The abundance of data gathered and stored has the power to affect businesses and communities greatly all across the world. That is where data science comes in to analyze it. Patterns and insights can be used to improve decision-making and develop more innovative products and services, which can help firms succeed in the marketplace. Perhaps most significantly, it enables machine learning (ML) models. Instead of relying solely on business analysts to extract insights from data, ML allows them to learn from massive amounts of information.
What is The Data Science Life Cycle?
If you want to learn how the project life cycle works, you can execute your own in a similar manner. We will now go over the steps of executing the method of a project in a real-world setting.
A data science life cycle is just a series of procedures that you must follow in order to finalize and transfer a product to your customer. Although the data science activities and the parties involved in installing and improving the system are distinct in each company, each life cycle will differ slightly. However, the majority of the projects follow a relatively similar methodology.
To start and complete a project, we first need to understand the various roles and duties of the people involved in building and developing the project. Let’s list the people involved in a project:
- Business Analyst
- Data Analyst
- Data Scientists
- Data Engineer
- Data Architect
- Machine Learning Engineer
Now we have an idea of roles. Next, it is time to focus on a typical business data science project.
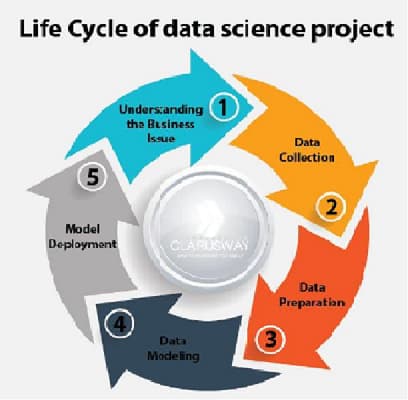
In most cases, data is the primary component of a project. You won’t be able to analyze or predict anything if you don’t have any data. It means you are dealing with something unknown. Therefore, before embarking on any project commissioned by one of your clients or stakeholders, you must first comprehend the underlying issue statement supplied by them. After identifying the business issue, we must collect data to help us solve the use case.
The process is very straightforward: the company data first, cleans it, then uses Exploratory Data Analysis (EDA) to retrieve key attributes, and then arranges the data through engineering and scaling. After a thorough examination, the model is developed and implemented in the second step. This whole lifecycle is not a one-man job; instead, the entire team must collaborate to complete the work while attaining the appropriate level of efficiency for the project. Let’s dig into the lifecycle some more.
1) Understanding the Business Issue:
First, it is critical to understand the client’s business problem to design a successful business model. For example, assume your client wants to forecast the churn rate of her retail business. You should first learn about her business, needs, and the goals she hopes to achieve with the forecast.
In such circumstances, it is critical to seek advice from domain specialists to comprehend the system’s fundamental issues. A business analyst is normally in charge of acquiring the necessary information from the client and delivering it to the data scientist team for further analysis. However, even a minor mistake in identifying the problem and comprehending the need can significantly impact the project, so it must be done with extreme care.
After asking the company’s stakeholders or clients’ necessary questions, you proceed to the following step, which is data collection.
2) Data Collection:
Once you have a clear understanding of the problem, you need to collect relevant data to break the problem down into smaller components.
The project begins with defining multiple sources of data (server logs, media postings, or from digital libraries, web scraping, and an Excel spreadsheet). Data collection comprises gathering information from various sources (internal and external) that can help solve a business challenge.

Typically, the data analyst team is in charge of gathering the data. Next, they must figure out how to gather and collect data properly to achieve the desired results.
There are two methods for gathering data: web scraping using Python and extracting data using third-party APIs.
3) Data Preparation:
After acquiring data from appropriate sources, you must proceed to data preparation. This phase assists you in gaining a better grasp of the data and preparing it for further analysis.
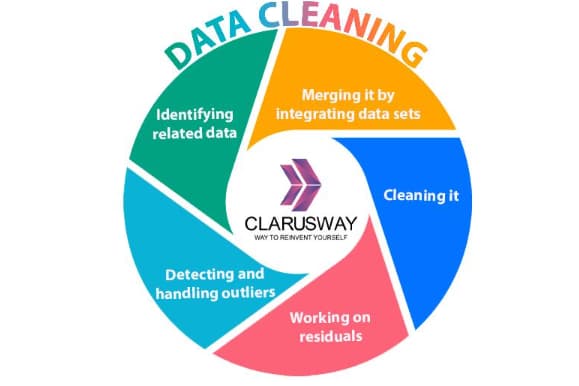
This phase is also called Data Cleaning or Data Wrangling. It consists of operations such as:
- Identifying related data,
- Merging it by integrating data sets,
- Cleaning it,
- Working on residuals,
- Detecting and handling outliers.
With the help of feature engineering, you can generate additional data and derive new ones from existing data. You then format the data to the required structure, and remove any extraneous columns or functions. It takes up to 90% of the project’s total time to prepare data, but it’s also the most critical life cycle phase.
At this point, exploratory data analysis (EDA) is vital since aggregating clean data allows for the detection of data structure, outliers, anomalies, and trends. These findings can help determine the optimum collection of features to apply and the appropriate algorithm to utilize to create and build the model.
4) Data Modeling:
Data modeling is regarded as the primary procedure. This data modeling procedure takes the provided data as input and strives to generate the required output.
You begin by selecting the proper type of model that will be used to obtain results, whether the challenge is a regression problem, a classification problem, or a clustering-based problem. Next, you select the appropriate machine learning algorithm that best fits the model based on the data provided. After that, you should fine-tune the hyperparameters of the selected models to achieve a desirable result.
Lastly, you test the model by putting it through accuracy and relevance tests. In addition, you must ensure that there is a proper balance of specificity and generalizability, which means that the produced model must be unbiased.

5) Model Deployment:
Before deploying the model, we must confirm that we have chosen the best option after a thorough examination. It is later delivered in the chosen channel and format. This is the final phase of the life cycle. To avoid unintended errors, please exercise extreme caution before executing each phase in the life cycle. For example, if you use the wrong machine learning technique for data modeling, you will not attain the needed accuracy and will have difficulty obtaining stakeholder support for the project. Likewise, if your data is not adequately cleansed, you will eventually encounter missing values in the dataset. As a result, comprehensive testing will be required at each stage to ensure that the model is effectively deployed and accepted in the actual world as an optimal use case.
Who Needs Data Science?
The objective of a mainstream business is to gain a deeper understanding of the processes and environment to correct in a much more reasonable timeframe. Just as that, a business will not build its transportation system itself preferring to hire a freight company to get a better “Return on Investment.”
The business intelligence (BI) sector operates only to provide solutions to these problems for their clients. The BI vendor’s goal is to determine which tools best serve the market. Then, to deliver those tools and show clients how to access and exploit them, the vendor must persuade the firm why the freight company is a better business option.
A company does not need to understand how transportation works, but its employees must be trained to adapt to a new system. Similarly, a company’s employees do not need to understand how an algorithm operates; they simply need to use that tool to acquire knowledge.
If the business intelligence company works well, learning will take place so that the clients recognize how to input algorithms and understand the results. Then, there is a black box that processes, similar to the black box that runs the lights, phones, and other essentials in the workplace.
Similarly, the artificial intelligence (AI) business and its deep-learning offshoot use the same phrase to designate the professionals who create deep-learning networks. The same challenges that exist in business intelligence also exist in artificial intelligence.
Consequently, the market is immediately constrained for “data scientists.” Most IT firms do not pay someone or a group to integrate algorithms into an application to make algorithms available.
The idea of focusing on how vast volumes of current business data can be better evaluated to improve corporate performance is fantastic, but it isn’t novel. It’s a standard feature in business software.
The individual or team typically referred to as the “data scientist,” who provides the deep, technical abilities required to transform modern mathematical models into practical business software, is vital to the BI and AI businesses – but not to the IT world as a whole.
Data Science Career Outlook
The Bureau of Labor Statistics (BLS) anticipates a significant increase in data science possibilities in the future years. Data science jobs are expected to increase at a 31% annual rate between 2020 and 2030.
While the number of positions may be lower, it is a highly skilled and in-demand career. Many companies are keen to hire experienced data scientists (of course, not data science masters); yet, enterprises are now having trouble filling these positions due to a highly competitive labor market for data scientists. Your data science certificate (such as IBM data science professional certificate) will make you stand out in this race. Despite the fact that there are fewer jobs in data science than in other occupations, this competition is expected to persist.
Increased job availability at the current rate is predicted to be available to data scientists as companies in the modern and digital world continue to require the ability to derive insight from increasingly enormous amounts of data for a virtually limitless number of applications.
What is the Data Scientist Salary?
According to BLS data, the median salary for data scientists (also known as “Data scientists and mathematical science occupations”) is $98,230. The lowest-paid 10% of data scientists made less than $52,950, while the highest-paid 10% earned more than $165,230, putting the employment in a highly affluent field of work when compared to all other occupations (May 2020).If you want a comprehensive data science resume, apply now for Clarusway’s data science course!